

The Two Faces of Abstraction:
Power vs. Hidden Dependency
Could we even work meaningfully with computers today without abstraction? From the very beginning, working with computers is simplified because otherwise their capabilities simply couldn’t be fully utilized. Too complex for daily work, and yet so powerful. In terms of programming, this has led to the emergence of new languages over the years, which, with modern compilers, make solving difficult tasks increasingly easier.
New Abstractions Constantly Emerge
New abstractions are also constantly emerging in the field of networking. Starting with DNS, because working directly with IPs is too cumbersome, or higher-level protocols for building high-throughput and scalable systems. All the way up to the highest levels, including compression.
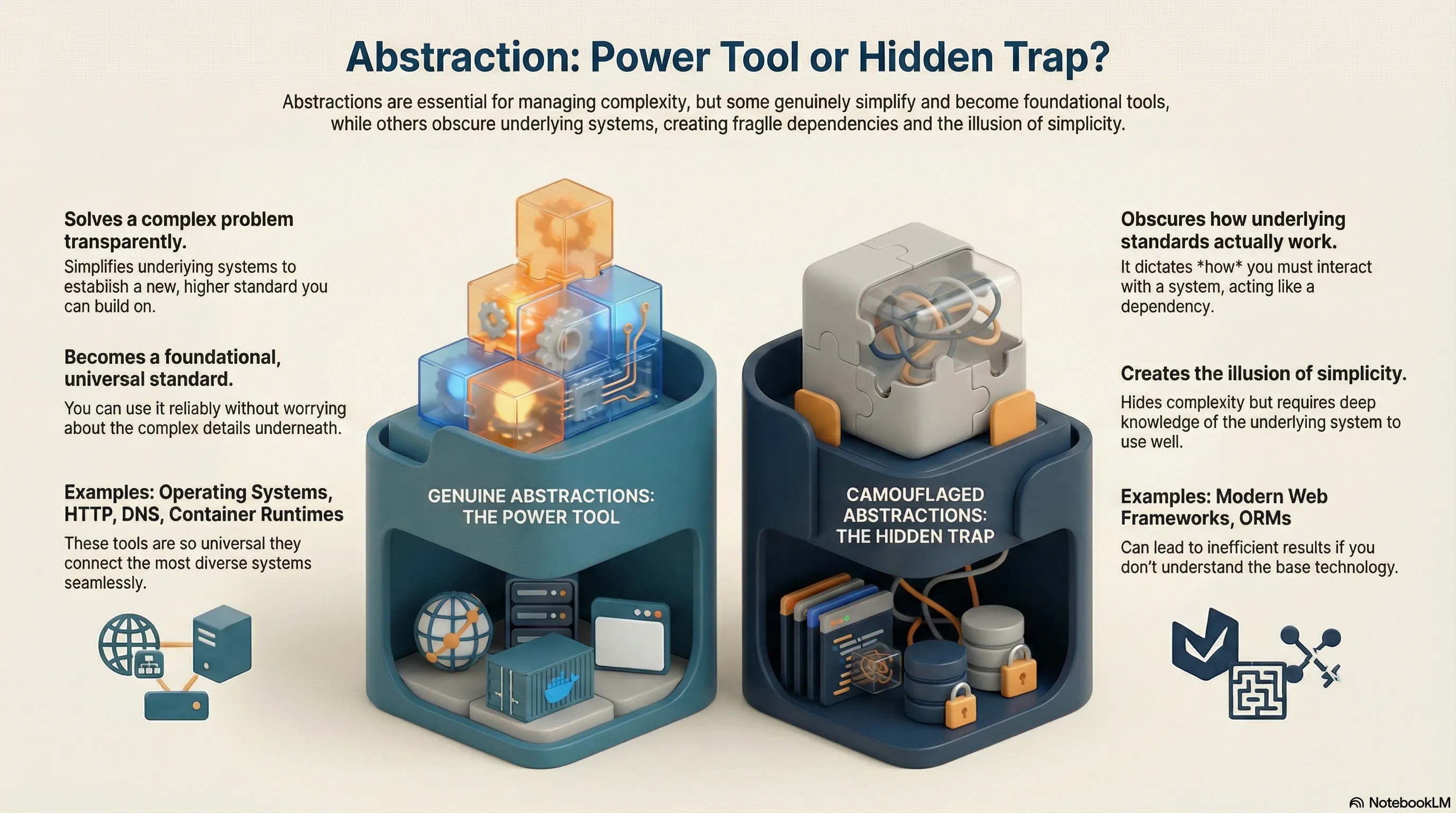
Conscious and targeted abstraction is precisely what makes it possible to bring this highly complex environment under control. Such an abstraction solves a higher-level problem and renders the complex processes completely transparent. Layers that build on such abstractions to simplify further complexity are often no longer transparent. When using them, additional knowledge of the underlying systems becomes necessary.
So What Exactly Are These “Genuine” Abstractions?
Your operating system represents an obvious abstraction of your computer. You don’t worry about syscalls, filesystem access, or the network stack. When writing your own software for it, it’s the high-level programming languages with their compilers or interpreters. You don’t translate your code into machine-readable form yourself or write your own runtime environment. You accept this abstraction as a given. Or consider defined standards at the network level like HTTP, TLS, or DNS. These are so universal that they can connect the most diverse systems. Container runtimes also fit in here. They abstract the use of cgroups or namespaces.
You simply use such abstractions without giving them a second thought. In your daily routine, you rarely, if ever, have to deal with the more complex details. They are a logical consequence of simplifying the underlying systems and thereby define a higher standard.
On the Other Hand, There Are “Camouflaged” Abstractions
In my view, such abstractions are more like dependencies. Because they dictate how you must interact with an underlying standard. They define best practices that you have to adapt to. And what’s worse: they are usually not transparent, but involve a complete penetration through all related areas. So you “should” already understand the basics to work really well with this dependency. Yet you are given the illusion that this is no longer necessary. And so, in the worst case, you merely learn to use a specific tool instead of the standards.
Take a modern web framework. Web standards—like the DOM or Browser APIs—are abstracted and packaged into a new, closed system. In the end, however, everything runs in a browser. But what this framework actually does remains obscured from you. Yet it directly affects you, for example, when you use the browser’s dev tools for debugging. It’s no coincidence that such frameworks often come bundled with the appropriate browser extension for these purposes. Or, for a project with database access, take an ORM. It’s supposed to abstract database access. If you truly don’t understand SQL, you won’t even notice what might need optimizing—if the ORM has generated inefficient queries for your use case. It may seem transparent, but at best, it obscures the real processes.
A Thin Line
An abstraction that does not solve a defined problem flawlessly and transparently is effectively just another dependency on the long list. Find such dependencies and identify how the underlying systems work. You will certainly discover things where you ask yourself why an additional layer was even introduced.
Further Exploration
-
The Fundamental Book on Abstraction in Programming Abelson, Harold, Gerald Jay Sussman, and Julie Sussman. Structure and Interpretation of Computer Programs. 2nd ed. MIT Press, 1996. This classic shows how we build complex systems from simple, understandable parts through proper abstraction.
-
The Law of Leaky Abstractions Spolsky, Joel. “The Law of Leaky Abstractions.” Joel on Software, 11 November 2002. The definitive essay explaining why all non-trivial abstractions eventually “leak” details from the underlying layers.
-
Hierarchical Abstraction in Systems Design Hennessy, John L., and David A. Patterson. Computer Architecture: A Quantitative Approach. 6th ed. Morgan Kaufmann, 2017. Demonstrates how abstraction is applied layer by layer, from transistors all the way up to large-scale systems.
-
The Philosophy of Complex Systems and Why They Fail Gall, John. Systemantics: How Systems Really Work and How They Fail (also known as The Systems Bible). 3rd ed. General Systemantics Press, 2003. A witty yet profound look at system behavior – highly relevant for understanding why we create abstractions and how extra layers can backfire.
-
Classic Example: The ORM N+1 Problem Stack Overflow discussion: “What is the N+1 selects problem in ORM?” A concrete, widely-known illustration of ORM performance pitfalls (inefficient queries). Further Exploration: