

When to Split a Monolith
and How to Connect the Pieces
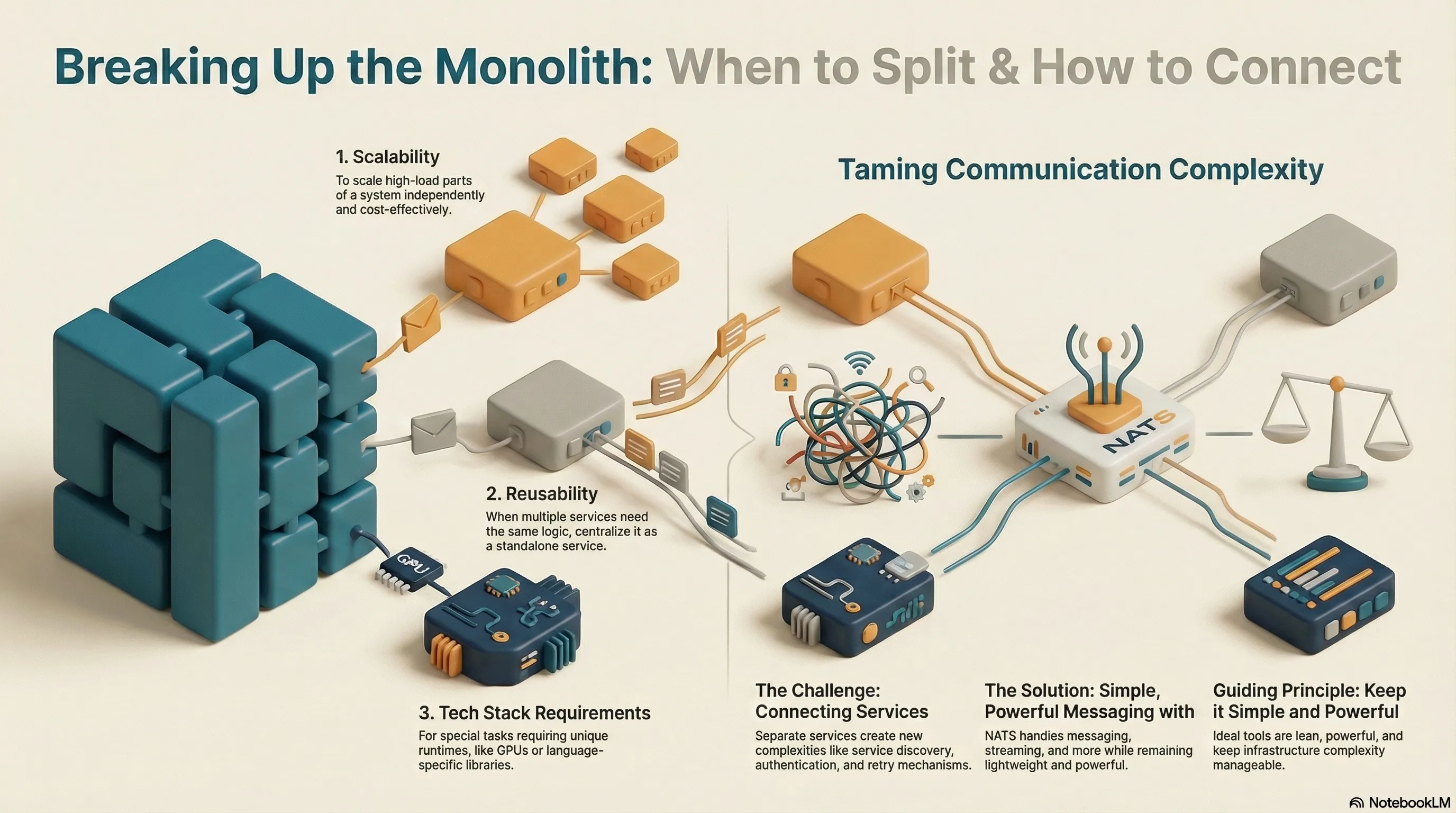
For me, there are effectively only three plausible reasons to outsource parts of a larger system into separate services:
-
Scalability: The load on a system is not uniform. If there are modules with special requirements, it’s worth extracting them. This allows you to scale only the relevant parts precisely and allocate resources in a tailored way—without operating the entire system unnecessarily expensively.
-
Reusability: When certain modules are needed by many different services, running them as a standalone service is significantly more efficient. Instead of duplicating the logic in every service, resources are calculated centrally, based on all dependent services.
-
Tech Stack: Some tasks come with special requirements—be it for the runtime environment, such as powerful GPUs, or for libraries that are only available for a specific programming language. In such cases, outsourcing to a separate service is not only sensible but often the only feasible solution.
Why Not Everything Needs to Be a Service
There is no reason to dogmatically insist on microservices or to outsource entire domains as a blanket rule. A modular monolith is perfectly fine. When projects decompose everything into services, I often wonder if the principles of clean code are perhaps not being sufficiently practiced there. After all, a service boundary enforces a clear separation of concerns—but the same order can also be achieved within a monolith.
The Communication Challenge
If you consciously decide on separate services (for one of the reasons mentioned), they must be able to communicate with each other. Even a single service can entail considerable complexity—networking them together often makes it worse. Services need to be able to discover each other; you need authentication, retry mechanisms, and more. This quickly becomes complex. In this process, an enormously simple approach is frequently overlooked.
A Simpler Approach: Job Queues and Messaging
I used to build many web APIs as monoliths with Symfony. When I started with Go in 2011, I could handle computationally intensive tasks significantly faster with it. However, I didn’t want to rewrite the entire services. Instead, I used Gearman—a brilliant tool. Gearman is based on a job server where workers register and offer specific functions that clients can then invoke.
Enter NATS
With the advent of NATS, I gradually replaced this setup. I initially used NATS in a variety of ways, sometimes even for service discovery: consumers would simply ask who offered which functionality, and the corresponding worker would respond with connection data.
Today, the most diverse scenarios can be mapped with NATS—messaging, streaming, request/reply, but also KV stores. It remains lightweight and is simultaneously incredibly powerful. The article “Why NATS” on the Synadia blog nicely explains why NATS deserves a closer look.
Conclusion: Keep It Simple and Powerful
In distributed systems, you need reliable tools. You can’t constantly reinvent everything. However, ideal solutions are lean, powerful, and keep the complexity of the infrastructure manageable.
Further Explorations
- Gearman: A versatile job server and distributed application framework. Its simple model of workers registering functions for clients to invoke makes it a powerful tool for offloading tasks and building custom job queues.
- NATS: A simple, secure, and high-performance open-source messaging system. Its core design of being lightweight yet powerful makes it ideal for modern distributed systems, cloud-native architectures, and microservices, supporting patterns from simple pub/sub to streaming and key-value stores.
- ZeroMQ: A high-performance asynchronous messaging library, often described as “sockets on steroids.” It provides a toolkit for building custom, lightweight messaging patterns without a central broker.
- Apache Kafka: A distributed event streaming platform designed for high-throughput, fault-tolerant, and durable pub/sub and stream processing. Ideal for log aggregation and real-time data pipelines.
- RabbitMQ: A robust, widely-adopted open-source message broker that implements the Advanced Message Queuing Protocol (AMQP). Known for its reliability and flexible routing capabilities.
- Envoy Proxy: A high-performance, open-source edge and service proxy. It is a foundational component for modern service meshes, handling service discovery, load balancing, and observability.
- Linkerd: An ultralight, security-first service mesh for Kubernetes. It provides zero-config mutual TLS, observability, and reliability features with minimal overhead.