

Beyond the Cloud Hype:
Building Resilient Systems
It’s October 20, 2025, and the world has come to a standstill. Well, okay, maybe it’s not that bad. But for a while, several—including some very well-known—internet services experienced major issues. The reason? Disruptions at AWS. Details are available in the AWS Health Dashboard.
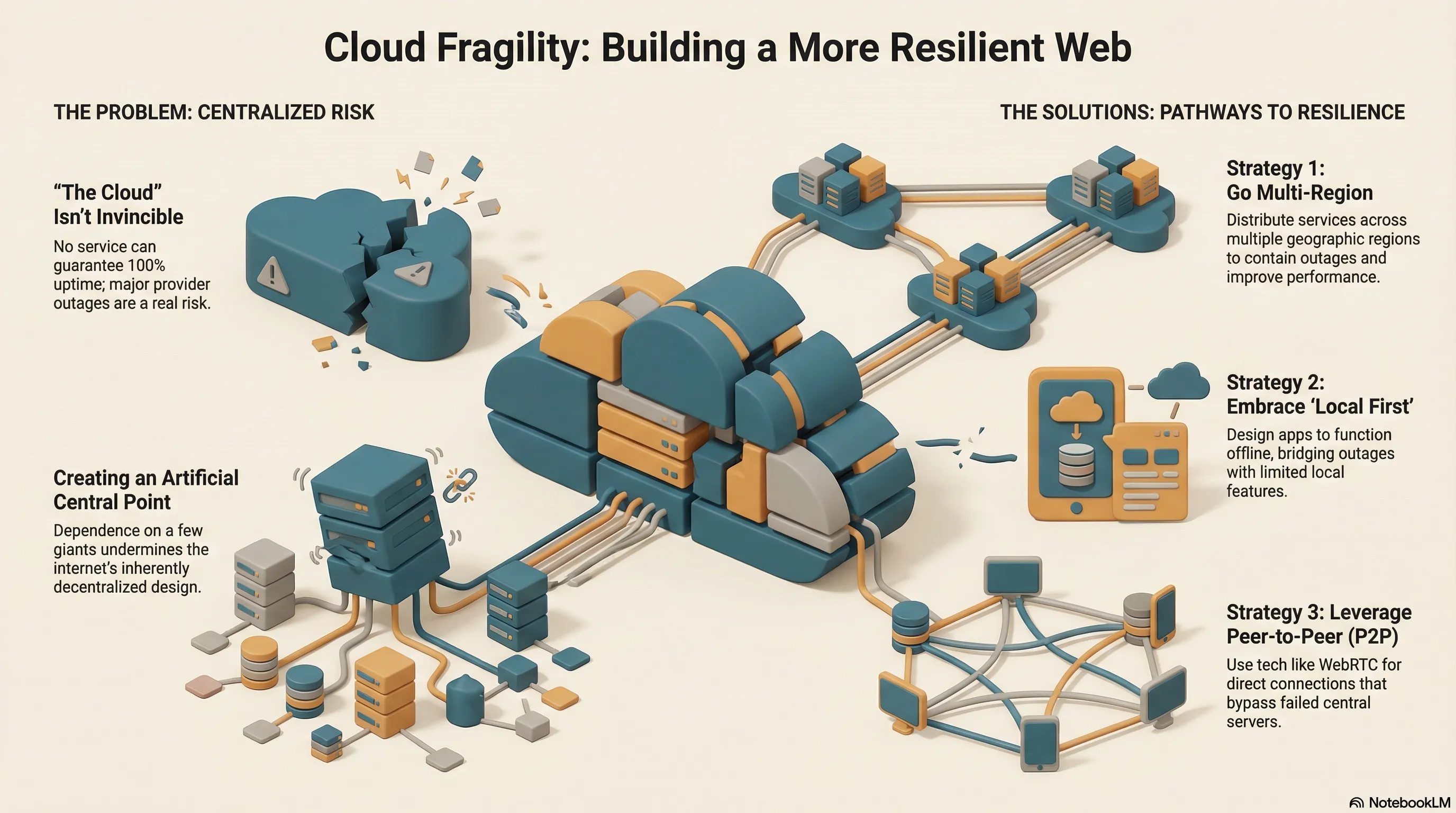
Regardless of the actual problem, this shows one thing very clearly: “The cloud” doesn’t have 100% availability either. No service can guarantee neither uptime nor data security.
By definition, the internet is completely decentralized. If parts of it go down, the rest keeps running. There’s usually a way to reach your destination, even if the direct connection is disrupted. But relying on just a few major cloud providers, without understanding the potential consequences, is risky. In effect, it undermines this decentralized approach and creates an artificial central point.
No matter which cloud provider you choose—that’s fine. It can simplify your personal setup. It can help you focus on your own solution. But at least spend some time thinking about the potential consequences. Whether you choose a cloud provider or self-host, if you serve everything from a single region, the risk of an outage is higher.
One solution is to distribute your services across multiple regions. Customers then have the added benefit of connecting to a service that’s as close as possible to their location, which improves response times. In the simplest case, if an outage occurs, only some of your users will lose access. It’s even better if distributed regions can compensate for the failure and affected users can be rerouted. Of course, such a setup is significantly more complex and costly. Data needs to be synchronized, and failover responsibilities must be clearly defined.
An alternative: Local First. Does your service really always need an active internet connection? Could an outage be mitigated by allowing the service to keep running locally/offline? This is possible even with modern web applications. Of course, you won’t be able to offer full functionality, but it’s another way to bridge an outage with limited features.
One more interesting approach is to use P2P to keep some core functions running without central components. You need an infrastructure that allows individual peers to discover each other. After that, no central authority is needed to establish communication. A well-known part of the web that enables this is WebRTC, which can create direct connections between participants.
Exploring these approaches might just be what saves your service the next time a major cloud provider has a bad day.